
Zur Durchführung moderner wissenschaftlicher Experimente sind komplexe und verteilte Detektorauslese- und Steuerungssysteme erforderlich. Die Instrumentierung integriert Experiment-spezifische und kommerzielle Komponenten von verschiedenen Herstellern und erzeugt zunehmend größere Datenmengen. Dabei wird eine Vielzahl unterschiedlicher Formate, Speichersysteme und Datenverarbeitungspfade verwendet. Oftmals ist eine korrekte Dateninterpretation und Qualitätssicherung aufgrund der enorm gestiegenen Anzahl, Größe und Komplexität der Datensätze manuell schwierig oder sogar unmöglich. Dies motiviert den Bedarf an automatischen oder zumindest halbautomatischen Datenanalysemethoden und -werkzeugen. Die Informationen über den Betriebsstatus und die wissenschaftliche Bedeutung müssen kontinuierlich aus dem Datenstrom extrahiert und den Benutzern in einer visuell leicht zu interpretierenden Form zur Verfügung gestellt werden.
Technologie
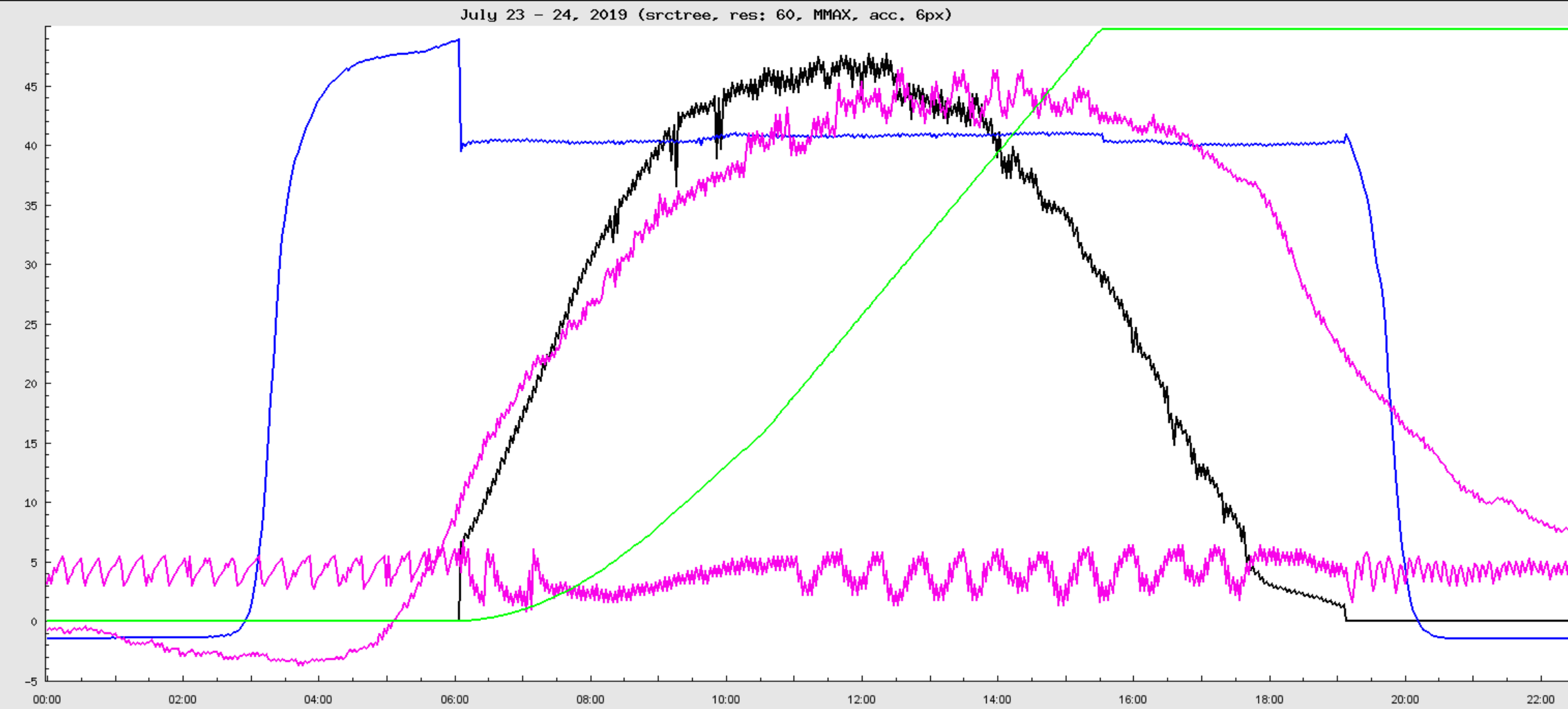
Wir entwickeln Systeme zur Organisation von Slow Control und Datenverwaltungsaufgaben in wissenschaftlichen Experimenten. Unsere Technologien zielen darauf ab, die von verschiedenen Subsystemen aufgezeichneten Daten zu integrieren und sie den Benutzern in einer einheitlichen, verständlichen und leicht zu bedienenden Weise zur Verfügung zu stellen. Der Schwerpunkt dieser Werkzeuge liegt aktuell auf Zeitreihen von skalaren Variablen, wie sie für Slow Control-Systeme typisch sind. Aber wir entwickeln auch Erweiterungen zur Handhabung mehrdimensionalen Datentypen, z.B. für räumliche Temperaturprofile, Magnetfeldmessungen oder Energiespektren.
Der Kern unserer RedHat OpenShift Plattform basiert auf Containern und Kubernetes. Die OpenShift-Infrastruktur ermöglicht es uns, eine Vielzahl von Prozessen, die von den internationalen Kollaborationen für ihre Experimente entwickelt wurden, zuverlässig zu betreiben. Diese Anwendungen benötigen in der Regel unterschiedliche Versionen von Programmen und Softwarebibliotheken. Diese können teilweise, auch durch die lange Laufzeit der Experimente, stark veraltet sein, manchmal sind sie leider auch nicht stabil. Die Containertechnologie ermöglicht es uns, die Softwareumgebung für jede Komponente zu kapseln, und die Auswirkungen im Fehlerfall zu begrenzen. Dies ist ein Gewinn die Stabilität der anderen Komponenten und des Gesamtsystems. Kubernetes bietet darüber hinaus Hochverfügbarkeit und Skalierbarkeit. Es startet ausgefallene Komponenten automatisch neu und verschiebt Komponenten, von ausgefallenen Knoten auf andere weiter verfügbare Knoten. Die Anzahl der laufenden Anwendungsreplikate kann manuell oder automatisch auf der Grundlage der aktuellen Last angepasst werden. Um die Entwicklung von Slow Control und Datenverwaltungssystemen zu erleichtern, entwickeln wir eine Reihe von Anwendungen, die auf der Kubernetes-Plattform oder unabhängig in einer Standard-Linux/Windows-Umgebung ausgeführt werden können. Unsere wichtigsten Anwendungen sind:
- Ein EPICS-basiertes Slow Control-System
- Der OPC-Archiver ist eine DOT.NET-Anwendung, die Daten aus dem Siemens WinCC-Steuerungssystem unter Verwendung des OPC-DA-Protokolls abruft und in einer Microsoft SQL-Datenbank archiviert.
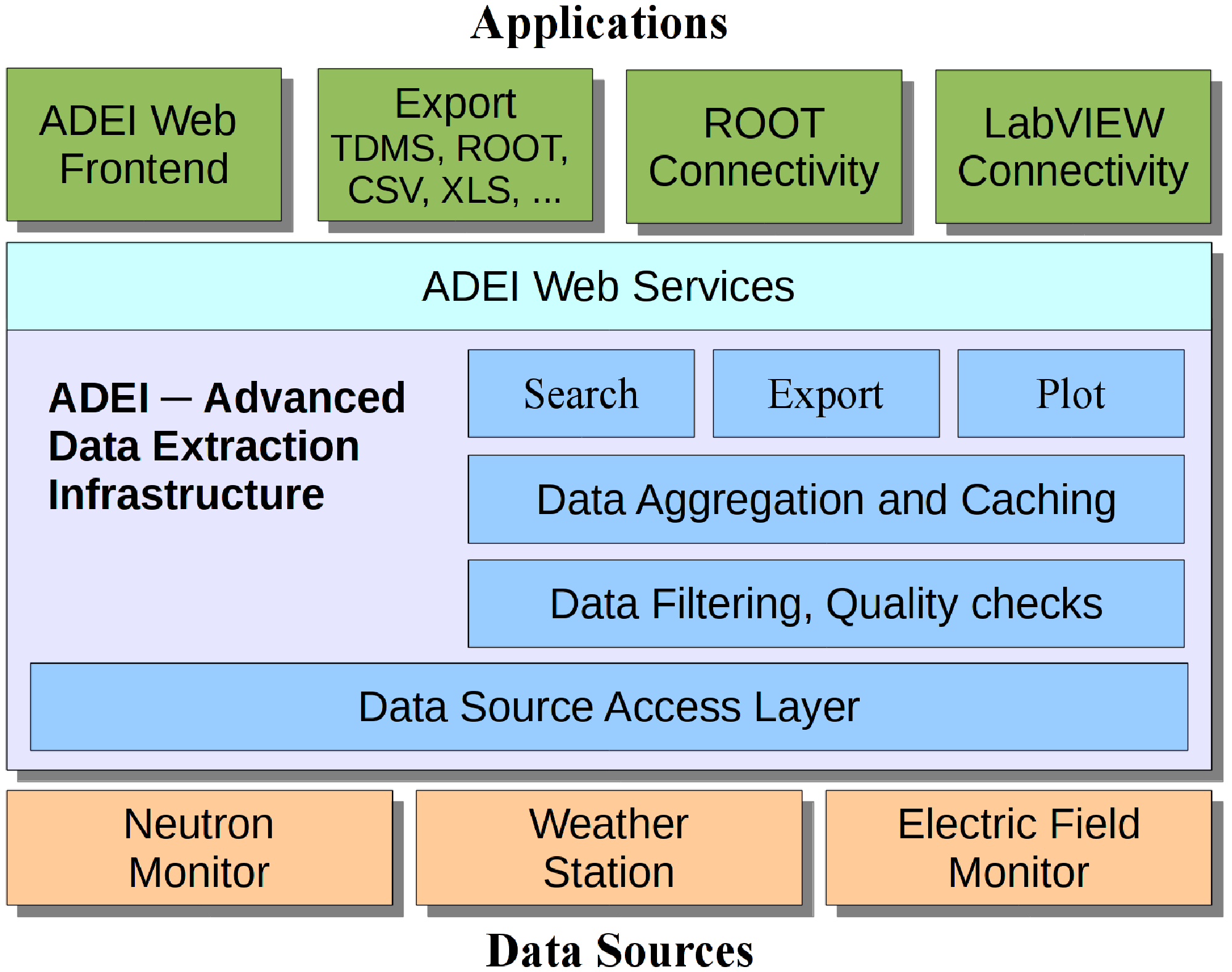
- ADEI (Advanced Data Extraction Infrastructure) - ist eine skalierbare Plattform zur Untersuchung, Verwaltung und Visualisierung großer Archive von Zeitreihendaten.
- BORA (personalisierte kollaBORAtive Statusanzeige) - ein Framework zur Generierung von Anwendungen, die den aktuellen Status des Experiments überwachen
- WAVe (Web-based Volume Visualization) - ein interaktives Visualisierungsframework für 3D-Datensätze
Um Slow Control und Datenverwaltungsdienste anbieten zu können, müssen wir eine Reihe von IT-Funktionen wie verteilte Speichersysteme oder Datenbanken bereitstellen. Viele der erforderlichen Dienste sind datenintensiv und ihre Leistung wird beeinträchtigt, wenn sie unter OpenShift ausgeführt werden. Wir erforschen derzeit die Möglichkeiten, datenintensive Anwendungen in einer Cloud-Umgebung effizient auszuführen. Die folgenden speziellen Themen werden untersucht:
- IT-Basistechnologien:
- Verteilte Dateisysteme für datenintensive Arbeitslasten (GlusterFS, CePH, BeeGFS)
- Datenbanktechnologien: relational (MSSQL, MySQL), für Dokumente (MongoDB), für Zeitreihen (InfluxDB), für Bild/Matrizen (TileDB)
- Cloud-Computing:
- Optimierung von Datenbank-Arbeitslasten für Cloud-Umgebung
- Ausführen von Windows-Anwendungen in einer Cloud-Umgebung
- Visualisierung:
- Bildverarbeitung
- Webbasierte Datenvisualisierung mit Spark, Jupyter und WebGL
Wir betreiben einen OpenShift-Cluster für das KATRIN-Experiment, der es der KATRIN-Kollaboration ermöglicht, vielfältige Anwendungen von der Datenerfassung bis zur Analyse zu realisieren. Es ist beabsichtigt die Infrastruktur in Zukunft auf andere Projekte auszuweiten und über Schedulingmechanismen eine faire Verteilung der Ressourcen zu gewährleisten.
ADEI: Advanced Data Extraction Infrastructure
ADEI ist eine skalierbare Plattform zur Untersuchung, Verwaltung und Visualisierung großer Archive von Zeitreihen. Das Ziel ist die Integration aller Kontrollsystemdaten, die von den verschiedenen Untersystemen eines großen wissenschaftlichen Experiments gesammelt werden und ihre einheitliche Darstellung. ADEI enthält eine Datenabstraktionsschicht, die es ermöglicht, Daten mit verschiedensten Formaten zu integrieren. Dabei können sich Datenquelle, wie z.B. Datenbank-Engine und Abtastrate signifikant unterschieden. Über eine RESTful API wird für die reibungslose Integration in den Daten-Workflow der Experimente sicher gestellt. Die Filter-, Such-, Visualisierungs- und Datenanalyse-Module basieren auf Caching-Strategien, um auch bei sehr großen Archiven eine interaktive Darstellung zu ermöglichen. Abhängig von der erwarteten Datenrate kann ADEI entweder auf einem einzelnen Server installiert sein oder über mehrere Knoten einer OpenShift-Cloudplattform skaliert werden.
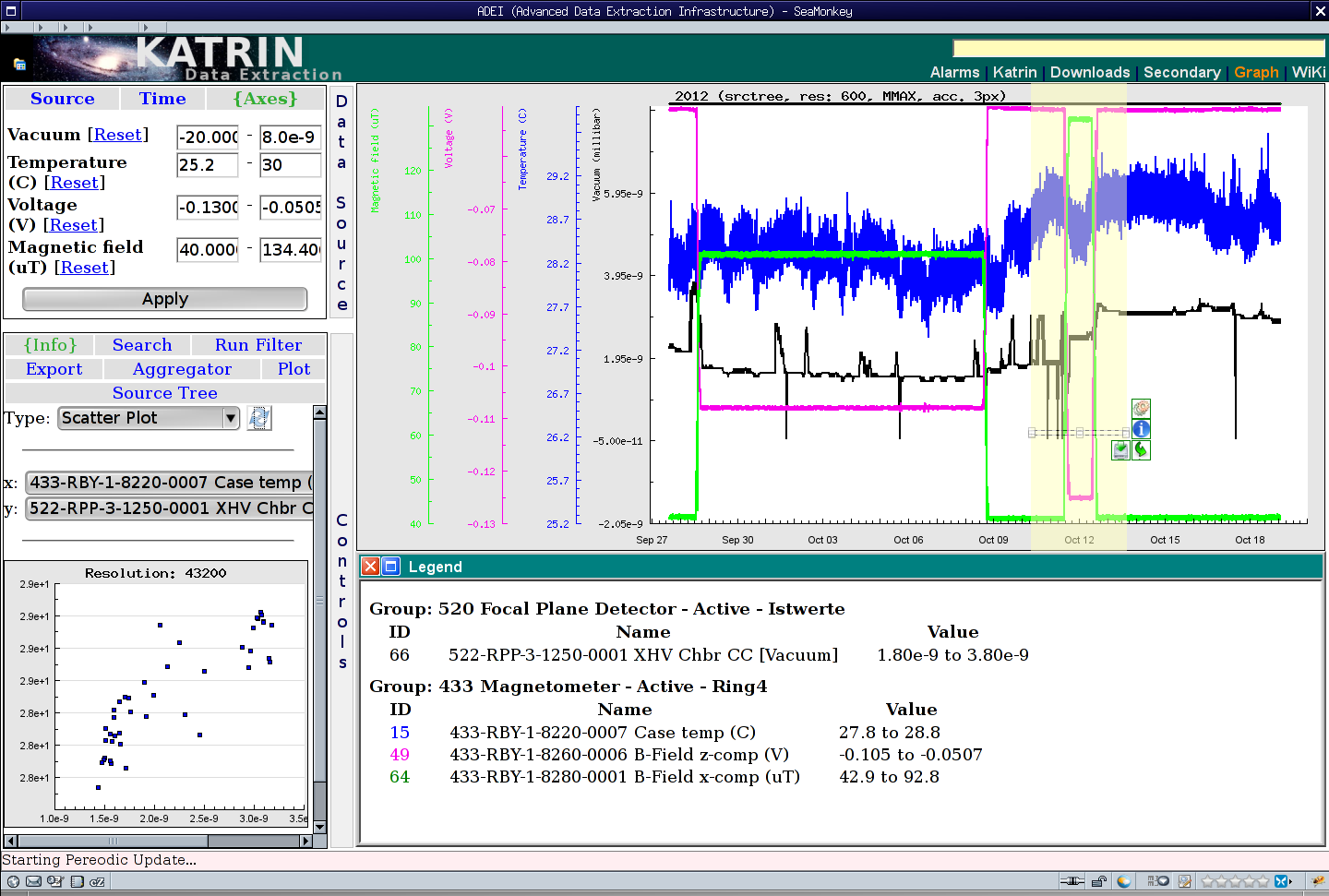
Das ADEI-Web-Frontend ist von der intuitiven Bedienung in Google Maps inspiriert. Einzelne oder mehrere Zeitreihen werden unter Verwendung eines hierarchischen Datenbaumes in einem frei wählbaren Zeitintervall geplottet. Anschließend kann in der Darstellung graphisch navigiert werden. Die dargestellte Ansicht kann für eine detaillierte statistische Analyse ausgewählt oder in eines der unterstützten Formate exportiert werden. ADEI integriert auch eine WiKi-Engine und eine einfache Schnittstelle für die statistische Analyse. Das WiKi bietet eine Möglichkeit, die Struktur der Daten zu beschreiben, und stellt spezifische Erweiterungen der klassischen WiKi-Syntax zur Verfügung, um automatisch Kanallisten oder Vorschaubilder zu generieren. Eine Reihe von Statistikfunktionen stehen in ADEI zur Verfügung, um erweiterte Informationen aus den Zeitreihen zu extrahieren. Über die Kreuzkorrelation lassen sich Abhängigkeiten zwischen verschiedenen Kanälen erkennen.
WAVe: Webbasierte Volumen-Visualisierung
Mit dem rapide wachsenden Umfang von wissenschaftlichen Daten gibt es Konzepte die Datensätze in zentralen Forschungseinrichtungen aufzubewahren und Cloud-basierte Dienste für die Datenanalyse anzubieten. Vor diesem Hintergrund entwickeln wir eine Online-Datenvisualisierungsplattform, die eine qualitativ hochwertige Vorschau der archivierten Daten ermöglicht. Durch die Kombination von Client- und Server-seitigem Rendering und einer mehrstufigen Cache-Hierarchie sind wir in der Lage, eine interaktive Visualisierung ohne Abstriche bei der Bildqualität anzubieten. Das entwickelte Framework unterstützt Volumen- und Oberflächen-Rendering und ermöglicht auch einen Zoom-on-Demand-Ansatz, bei dem nur ein ausgewählter volumetrischer Bereich mit höheren Details neu geladen wird.
Um ein robustes Visualisierungssystem bereitzustellen, entwickeln wir eine Reihe von Technologien:
-
Datenbanken und effiziente Organisation von 3D/4D-Bilddaten
-
Standard-Bildverarbeitungsmethoden, z.B. Entfernung von Hintergrund, Rauschunterdrückung, etc.
-
Grundlegende Segmentierungsmethoden zur Entfernung von Umhüllungen und Tragstrukturen um die Objekte herum
-
Bild- und Videokompressionsverfahren
-
Remote-3D-Visualisierung mit WebGL mit besonderem Schwerpunkt auf adaptiver Qualität, progressivem Laden und schnellen Rendering-Methoden
-
Analyse der Benutzerinteraktion mit dem Ziel der Entwicklung von KI-Methoden zur Anpassung des Darstellung auf der Grundlage des Benutzerverhaltens und der Interessen, z.B. durch adaptive Bildkompression
Experimente & Projekte
-
Edelweiss – Suche nach dunkler Materie
-
Meteorological instruments (KIT Cube & Weather Tower)
-
Energy storage (BESS)
-
TOSKA – Testanlage für supraleitende Komponenten
Für Studierende
Wir bieten ein breites Spektrum an Bachelor- und Masterarbeiten im Umfeld der Technologien an, die in unseren Projekten verwendet werden. Die Themen reichen von Datenbanktechnologie bis hin zu Cloud Computing, Bildverarbeitung und webbasierter Visualisierung. Die aktuellen Angebote werden auf der IPE-Website veröffentlicht oder können bei uns erfragt werden.
- Masterarbeiten im IPE
- Hiwi & Praktika im IPE