
Alps: Advanced Linux PCI Services
Contact: Dr. Suren Chilingaryan

Building data acquisition systems for PCIe devices with high-bandwidth is challenging: the Linux kernel driver interface is volatile and kernel drivers are hard to develop and to maintain. Additional complexity is added by the necessity to synchronize the development of detector hardware and the required readout software. Due to limited bandwidth of system memory, effective streaming of data requires an efficient realization of the DMA protocol. If feedback loops are desired, a large amount of computing resources must be available to process a dense stream of information. This is often provided by GPUs. To reduce latency, a direct communication between detector electronics and GPUs might be established using NVIDIA GPUDirect and AMD DirectGMA technologies. Another important aspect is the storage and preservation of the produced data. The storage subsystem should be able to handle a data stream of multiple gigabytes per second continuously. Solving all these questions requires expertise in different areas covering hardware and system design, as well as software engineering.
Technology
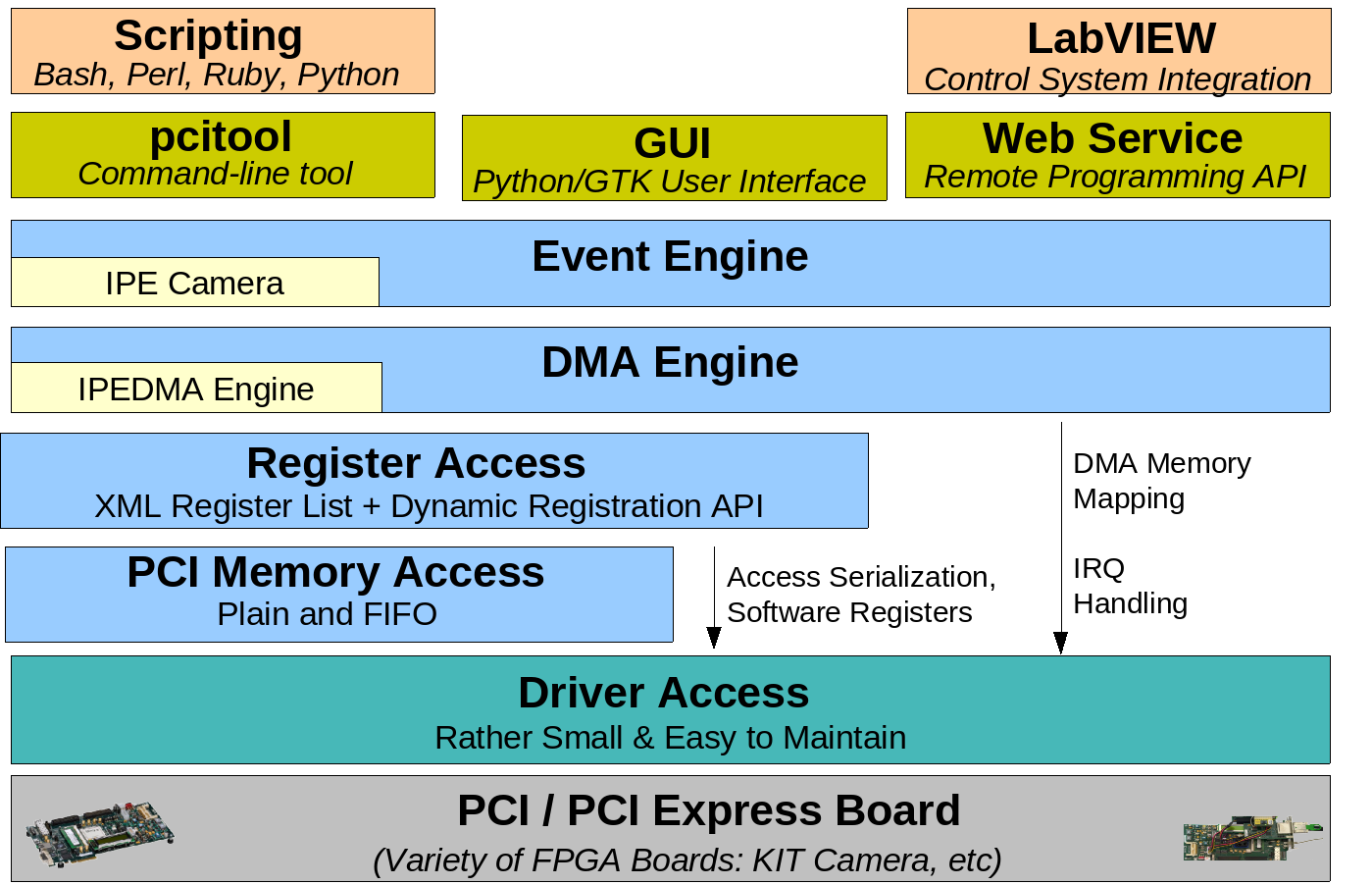
Advanced Linux PCI Services (Alps) is a driver platform intended for development and debugging of in-house PCIe-based electronics. It allows one to quickly roll out stable and efficient drivers for newly developed electronics. The functionality of Alps includes a flexible register model with scripting support, modular scatter-gather DMA engines, and low-latency RDMA communication with GPUs using GPUDirect and DirectGMA technologies. The Alps platform is currently used by the IPE streaming camera and also for development of beam monitoring devices KALYPSO and KAPTURE.
In order to reduce cost of driver maintenance with ever evolving Linux kernel versions, Alps consists of two components. A tiny kernel module responsible for interrupt handling and management of DMA buffers. But most of the functionality including implementation of DMA protocols is kept outside of the kernel in a user-space library. Despite of the user-space implementation, we fully sustain data rates supported by currently used electronics. We were able to achieve 12 GB/s data flow using PCIe gen3 x16 interconnect. On top of the library a flexible scripting interface with rich debugging capabilities is provided.
The user-space library provides several API layers. The register access layer provides methods to read, write, and modify hardware registers. The list of registers is defined in an XML file and can be extended or modified even at run time. By default, registers are located in an IO-mapped memory region (or in multiple regions) associated with the electronics and a standard Linux API is used to access the memory. Custom registers requiring different access protocol are implemented with plug-ins and once implemented can be later configured in XML as well. The DMA engine layer is a pluggable interface to implement DMA protocols. The DMA plugin must only implement the logic to interact with the FPGA-specific DMA registers. The management of the DMA buffer is handled by the library. The event engine layer defines an event-based model to integrate device-specific code again with plug-ins. Each device can define multiple events and, for each event, several data types. The events will be triggered in hardware or requested by software. The client application may subscribe to get event notifications. Upon event notification, the application can request the desired type of data.
To gain the full advantage of large blocks supported by modern file systems and to avoid performance penalties by the standard POSIX stack, we have developed the data-streaming library “FastWriter” based on Linux AIO API. It allows us to record data at rates of up 3 GB/s reliably using either a small SSD raid or a remote magnetic storage accessed over iSER protocol. To enable online data processing and low-latency feedback loop, support for the DirectGMA and GPUDirect technologies is included. DirectGMA realizes the direct communication between custom electronics and the professional series of AMD graphics cards directly via PCIe bus. The technology is implemented as extension of OpenCL standard and is fully integrated into our UFO parallel processing framework. GPUDirect is NVIDIAs counterpart providing a significantly better communication latency.
The Alps platform reflects the versatile character of the hardware design process. New hardware is easily included by describing register model in XML. A once implemented DMA protocol can be easily re-used for multiple hardware projects. Any changes in the hardware design require only corresponding adjustments in the XML configuration. Even the DMA engines can be easily re-configured without the need to modify the driver software. By providing a stable driver platform, we eliminate uncertainty about the source of the errors: the hardware developers can be sure that software is working correctly and focus on tracing hardware problems.
Projects
- CMS
- KALYPSO
- CAPTURE
- NeoDyn
- PANDA
- UFO