

Computational demands are rising rapidly across all fields of scientific research. With the increased complexity and data rates of modern detectors, sophisticated computing systems need to be an inherent element of data acquisition and control systems. As result, online image reconstruction and analysis enables the design of sophisticated experiments. Scientists will get instant overview of the experimental results and they are able to control processes under study based on visual information either in automatic or manual fashion. Furthermore, on a 10-year horizon we are looking for the detectors generating terabits of data per second. The performance of storage systems fails far behind. This makes it necessary to identify and extract the data of a scientific relevance already during data acquisition phase and perform further data compression whenever is possible.
GPUs are excelling general-purpose processors both in terms of the rate of arithmetic operations and memory throughput. Moderate prices, possible due to a large gaming market, made GPUs an important device in scientific computing. Recently, several technologies were presented to adapt GPUs also for embedded and real-time applications. NVIDIA GPUDirect and AMD DirectGMA enable direct communication between GPUs and other components of data acquisition system and booth data throughput. The impact of non real-time operating systems is, consequently, eliminated and the communication latency is made both small and predictable. This opens a way to use GPUs as part of real-time instrumentation for detector control and data acquisition, including trigger applications, data reduction, online monitoring, etc.
To fully exploit the performance of recent GPUs dedicated code is required. A number of development models were presented to simplify GPU programming. Recently, the OpenMP specification was extended to allow pragma-style notation to offload compute-intense parts of applications to GPUs. OpenCL and similar NVIDIA-specific CUDA models use explicit control of parallelism and allow to achieve far better performance. However, the GPU architecture changes rapidly. A significant performance improvements are possible if details of a specific GPU architecture are taken into the consideration. This is particularly important for real-time applications with critical latency requirements. Often, just scaling a number of GPUs is not enough to bring latency down and the only way to fulfill the requirement is to design highly efficient implementation. We are analysing internal and often undocumented details of recent GPU architectures and look for ways to optimize scientific codes also using automated adaptive codes which relay on the GPU specification and online micro-benchmarking.
Technology
At IPE we have a broad range of expertise in parallel algorithms, computing models, and hardware architectures. For our research and development we operate a cluster equipped with several generations of GPUs from AMD and NVIDIA.
The main areas of research in IPE include:
- Heterogeneous computing with CPUs, GPUs, FPGAs, and custom accelerators
- Reduced-precision computations and hardware-aware techniques
- Parallel programming with CUDA and OpenCL
- GPU and detector intercommunication with GPUDirect and DirectGMA
- Benchmarking, performance analysis, and software optimization
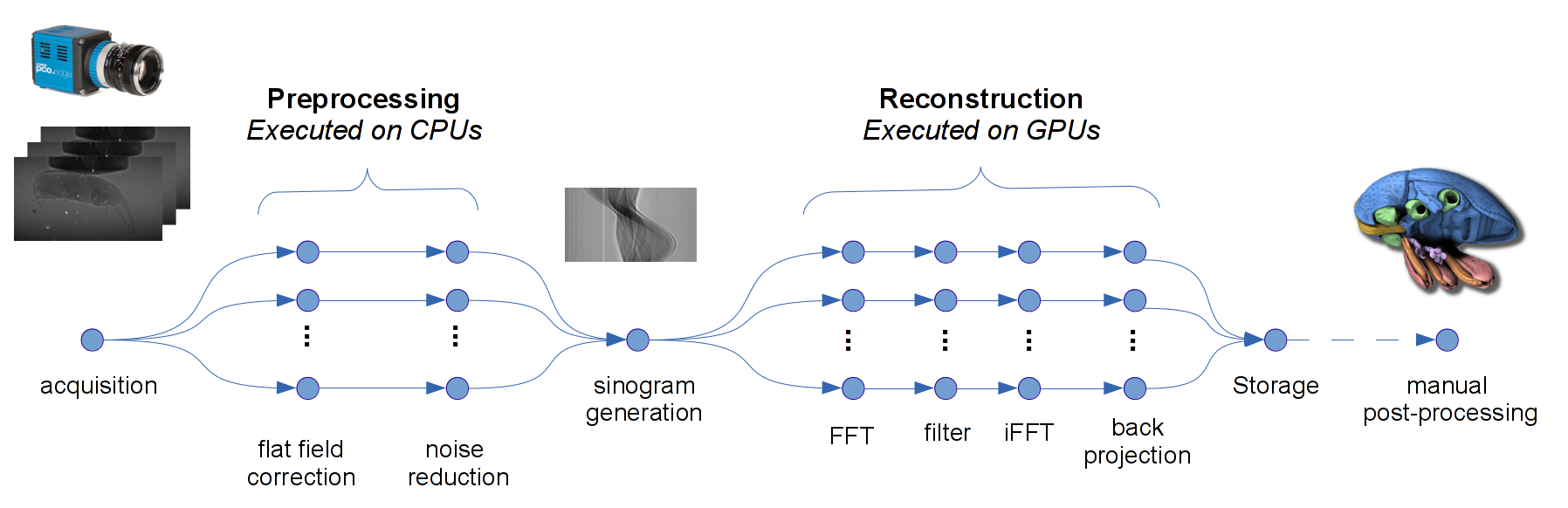
Focus of our applications is online data-processing, control, and monitoring. One prominent example of our activities is GPU-based control system for online X-ray and ultra-sound tomography which is currently at production high-throughput imaging beam-line at KARA research synchrotron. The central element of the system is the pipelined UFO image processing framework. It models the image processing workflow by a structured graph where each node represents an operator on the input data. By design, the UFO framework contains multiplelevels of parallelism: fine-grained massive parallelism, pipelining and concurrent execution of branches within the graph. The implemented library of image processing algorithms is implemented in OpenCL and carefully optimized to recent architectures from AMD and NVIDIA. The achieved reconstruction throughput reaches 6 GB/s for tomography and about 1 GB/s for laminography using a single reconstruction node only.
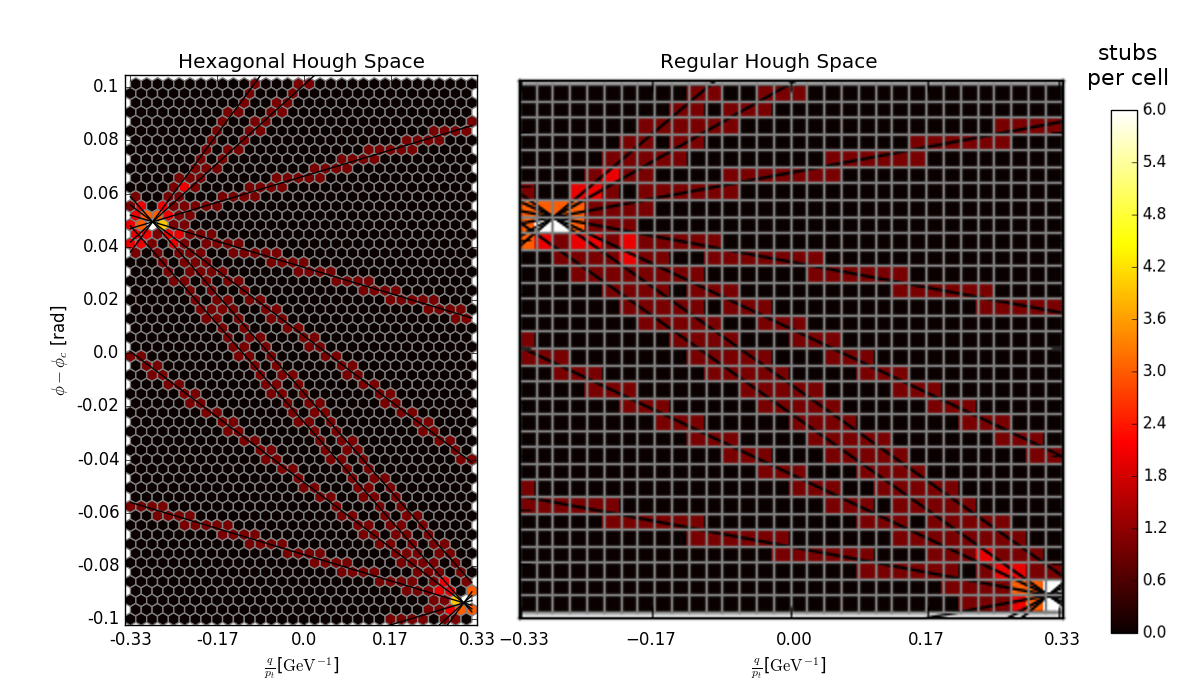
Another our flagship project is a GPU-based prototype of L1 track trigger for CMS experiment. With upcoming high luminosity upgrade, the amount of data produced by the detectors of Large Hadron Collider (LHC) at CERN are expected to be in the range of multiple terabits per second, with new impact events every 25ns. In order to analyze and process such huge amounts of data, it is essential to have efficient data reduction mechanisms in place. One mechanism is to trigger readout only for some particle trajectories in the detector. Traditionally FPGAs and ASICs are used to reconstruct particle trajectories in real-time and veto all but the relevant ones. We performed a case-study aimed to evaluate possibility to use much more flexible GPUs for this task instead. A trigger prototype was developed. It uses GPUDirect and DirectGMA technologies to distribute the track candidates from FPGA-based electronics to multiple GPUs which reconstruct tracks and signal FPGA if the track is accepted. The target latency of 6 us was achieved using the GPUDirect variant. The technology allowed us to use more precise hexagonal grid for track finding. The traditional FPGA technology is limited to regular square grid due to complexity.
We also have applications in material science and fluid mechanics.
Projects
For students
We can offer a variety of research topics for candidates interested in GPU computing, parallel algorithms, performance analysis, and software optimization. We continuously propose internship on “optimization of various image-processing algorithms for recent parallel architectures including CPUs, GPUs, and FPGAs”. Frequently, we also offer more specific topics for Master thesis within ongoing projects.
We generally expect prior exposure in parallel programming. We will be happy to welcome you at IPE if you are proficient in C and have some experience in CUDA/OpenCL or/and multi-threaded programming. If you have the required experience and are able to work independently, we are also flexible to adapt topics for your interests and even might sketch a new topic within domain of high-performance computing.